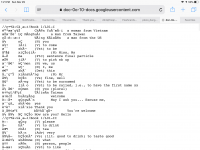
These are flashcards for books 1-5 of 當代中文課程 (A Course in Contemporary Chinese). This is the new series from 師大 that's supposed to supersede their AV Chinese series. Cards contain traditional characters only, a reasonable assumption you're using if you use this book.
Category name format example: //當代中文/Book 2/L05-I
The innermost category's suffix (the -I or -II on L05-I) for each lesson denotes which group of vocab in the lesson it came from -- each lesson has two groups of vocab.
Download: https://drive.google.com/file/d/1MmchpQiLgdbAeqwTASframYesKcs-ADi/view
Details:
I scraped these from the official vocab slides, then edited a few things manually here and there (mostly errors in the English).
Since the scraping was error prone (pptx -> pdf -> txt followed by some hacky text processing) the pinyin was verified against the characters by checking if the reading specified in the slides is a valid reading of the character it's matched to---this revealed a few transcription errors that I fixed manually. There's still probably minor errors in the English like collapsed/separated words, but shouldn't be a big deal if you're just using them as flashcards or to look up what level a word is. If it's useful to anyone, I might throw the code online at some point.
Also, there might be an issue with the same word occurring multiple times that'd need to be resolved when importing, but I didn't pay too much attention to that.
Category name format example: //當代中文/Book 2/L05-I
The innermost category's suffix (the -I or -II on L05-I) for each lesson denotes which group of vocab in the lesson it came from -- each lesson has two groups of vocab.
Download: https://drive.google.com/file/d/1MmchpQiLgdbAeqwTASframYesKcs-ADi/view
Details:
I scraped these from the official vocab slides, then edited a few things manually here and there (mostly errors in the English).
Since the scraping was error prone (pptx -> pdf -> txt followed by some hacky text processing) the pinyin was verified against the characters by checking if the reading specified in the slides is a valid reading of the character it's matched to---this revealed a few transcription errors that I fixed manually. There's still probably minor errors in the English like collapsed/separated words, but shouldn't be a big deal if you're just using them as flashcards or to look up what level a word is. If it's useful to anyone, I might throw the code online at some point.
Also, there might be an issue with the same word occurring multiple times that'd need to be resolved when importing, but I didn't pay too much attention to that.


")
