Hello
I use Screen-OCR-floating-button satisfactorily.
But today I notice that it cannot recognize a certain character 儿 (zhèr).
See the screenshot.
Why?
I "enter" the Chinese sentence directly to Pleco .. Pleco recognizes 儿(zhèr) without problem.
Thank you.
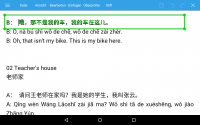
B: 哦,那不是我的车,我的车在这儿。
B: Ò, nà bú shì wǒ de chē, wǒ de chē zài zhèr.
B: Oh, that isn't my bike. This is my bike here.
I use Screen-OCR-floating-button satisfactorily.
But today I notice that it cannot recognize a certain character 儿 (zhèr).
See the screenshot.
Why?
I "enter" the Chinese sentence directly to Pleco .. Pleco recognizes 儿(zhèr) without problem.
Thank you.
B: 哦,那不是我的车,我的车在这儿。
B: Ò, nà bú shì wǒ de chē, wǒ de chē zài zhèr.
B: Oh, that isn't my bike. This is my bike here.