Would be great if those words of the day (or even morning/afternoon/evening) could be taken from a person's own specific flashcards.
If we did that it would definitely make sense to customize it, yes.
If I am interested in looking up names, I usually do either a fulltext search, or search for the hanzi directly. It's not uncommon to see 2 or 3 of the top list items wasted on surnames or country abbreviations, out of 8 visible on my 5 inch phone (with the keyboard open). On top of this some dictionaries use all lowercase for names anyway which adds to the mess.
Should definitely be optional, yes.
So unless there is already a way and it's me that hadn't noticed yet, it would be nice to have a search function on while browsing example sentences.
We're not planning to add a search box to the definition screen but we do now support direct search of example sentences from the main screen in 4.0 so you should be able to rig up something like this then.
1. In normal dictionary search, it would also make sense to be able to search for multiple full-text strings like #虽然#但是, and also filter matches you don't want, perhaps an exclamation mark like #可!#可是 in analogy with !=
Already supported for 4.0, yes, though the negating is still a little buggy and I can't promise it'll be supported initially.
Great! Will it be manual or automatic though?
It won't automatically upgrade old cards to include all linked entries, but the remap function will indeed populate all of them.
I understand Mike's reasoning about cluttering but I think too that this is an important function that can be expanded later on.
That was more of a retrospective kind of reasoning, to be honest - at this point I'm (maybe naively) feeling like we're close enough that it really would be a waste to put more work into adding features to 3.x, so I don't think we're likely to add anything this ambitious to it now.
But I wish that, say, 5 years ago, after we'd finished up 3.0 on iOS/Android, we'd started churning out a steady series of annual 3.x updates adding the half dozen or so most popular not-impossible-in-our-existing-app feature requests each year and then quietly working on 4.0 between those updates - 4.0 might have taken a year or two longer that way, but I don't think people would have minded that much if they were getting a lot of their needs met in the meantime.

")
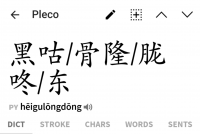

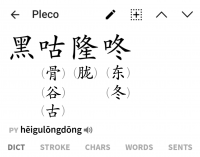


")

